
声明:本文来自于微信公众号 数字生命卡兹克,作者:数字生命卡兹克,授权站长之家转载发布。
做AI自媒体的人,读前沿学术论文,跟着补课,提升自己的知识体系自然是少不了的。
仅仅是为了跟上这个时代,就已经得拼尽全力不掉队了。
但是吧,不怕各位笑话,我的英语真的很差,最熟练的喊出来的那句英语是:
I'fine,thank you,and you?
真的,在读各种文献的过程中,即使已经用大模型加持翻译了,但是还是受尽了各种折磨。
就比如昨天豆包发了个AI图像的论文。

我寻思着翻一下之前他们SeedEdit的论文,对照着学习一下。

就是这个。
别的论文我不太懂,但是这类AI的论文呢,一般上下文逻辑咬的很死,并且充斥着大量高度专业化的术语和学术表达。
像是:Out-of-Domain (OOD) 、DiT架构这类词很多。
光是专业学术用语部分,倒也还好。但遇见一些专业术语搭配复杂表达方式的文段,我说实话,我现在一般用沉浸式翻译搭配OpenAI或者DeepL的API,翻译起来还是懵逼。

很多时候,它对于专业术语,即便不懂也要硬翻。对于我这种非专业的人来说,看起来就真的很费劲。
正好最近又看了玉渊潭天做的关于AI翻译质量的策划,非常牛逼。所以我也想,不如我自己也评测一下。
看看在这个场景下,到底哪个大模型,翻译质量最好。
说干就干。
于是,我跟小伙伴肝了2天时间,测了N多题,找到了我们认为,目前翻译效果最好的大模型。
直接说结论:网易有道这个老牌翻译厂商出的AI大模型子曰翻译2.0,居然吊打了一切。。。
说说我们是怎么测大模型的翻译评测这块的。
测试的维度也很简单,就从我平常受到的折磨体验出发,梳理出了2点。
这些AI必须:
1. 说人话;2. 没活别瞎翻。
第一点,说人话。好解释,翻译内容符合中国人的语言习惯。
第二点,没活别瞎翻,就更好说了。专业术语和一些专有名词,要是不会翻可以不翻,但别硬翻。其他内容基本正确就行。
在选手上,我选了海外的Grok3,ChatGPT-4o、Claude3.7、Gemni2这标准四人组。国内我把能跑的也都跑了,不过受制于篇幅,文章里面我就只展示DeepSeek R1、智谱GLM-4、有道子曰翻译2.0、Qwen2.5-Max这四人组了。
DeepSeek R1是唯一一个推理模型,虽然理论上我也不应该用推理模型来测翻译,因为不实用。。。但是谁叫人实在太火了呢= =
我给这这些大模型出的第一道题,就是SeedEdit这篇论文里的一个稍微复杂点的段落,涉及了一堆高频专业术语,还包含学术引用信息、作者姓名。

先看国产。
说人话方面。
Qwen和智谱GLM在说人话上都需要加强,最具代表性的句子就是这个:
Qwen:我们注意到,我们的方法主要聚焦于HQ-Edit基准中的应用场景,在这些场景中,我们希望根据任意指令对T2I生成的图像进行修改。
智谱GLM:我们注意到,我们的方法主要关注 HQ-Edit 基准中的应用场景,我们希望用任意指令修改 T2I 生成的图像。
一个句子中就能出现三个同样的主语,读起来就非常的难受,并且断句也很奇怪。
子曰翻译2.0的表现倒是非常的棒。它的主语滥用较少,避免了一大坨过度重复的代词。尤其在处理“that”和“where”这类句式时,表现不错。
DeepSeek比起子曰翻译2.0,人话输出上稍微弱了一点,翻译腔的机械感重了一点。很明显的例子就是第一句话,不够简洁,主语消失了。
没活别硬翻方面,子曰翻译2.0和DeepSeek都明显好一点。
对Out-of-Domain (OOD) test的处理上,只有Qwen翻译成了跨领域测试。智谱GLM和Qwen对real in-the-wild image inputs的翻译都有点难顶。。。其实,直接翻成真实场景的图像输入就行。

国外组这边,在英译中的表现上都要比国内组的要稍微差点,那英式中文的感觉实在挥之不去,读起来非常的不流畅。
这里面表现最好的就是ChatGPT-4o。它的翻译整体上是清晰且准确的,算是比较好地展现了原文的技术内容和学术语气。
Gemini和Claude基本属于一个级别的,人话输出差点儿意思。
Grok3的表现也还行,但还是那个老毛病:主语疯狂堆叠。

这第一道题还只是学术论文中,比较“正常”的一段,理解语义的难度不算太高。
但是当你看硬核技术论文的时候,我不知道你们有没有跟我一样的感觉:AI面对正文中的内容时,表现可能还好。但当对象变为图注内容时,很大概率开始抽风。
因为SeedEdit这篇论文里,图注部分没有什么复杂的段落,我就从经典神文《Attention is all you need》里摘出来了一段,作为第二道大题。
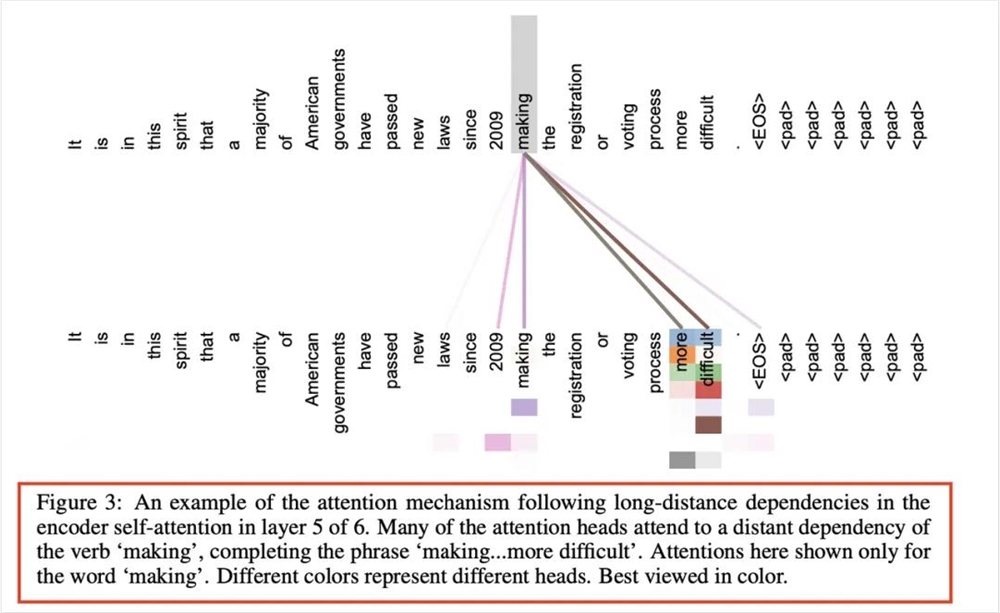
这回,就能很明显地感受到各个AI大模型在面对这种隐性语境限制的情况下,翻译英文的能力了。
开头的第一个长难句,其实就是对图片的一个总结,怎么简洁怎么来。

智谱GLM对图注语境下的长难句的理解有点不到位。
DeepSeek、Qwen则选择在中间进行断句,无功无过。但是在结尾处,这两位都选择“建议以彩色查看”,在学术语境中语气稍显随意了些。但也没大问题。
子曰翻译2.0在一句话的表现非常简洁,很符合一个正常学术图注的规范。但是,也出现了个小问题。因为heads这个单词在前一句出现过了,子曰翻译2.0直接在下一句省略了,给翻译成了不同颜色代表不同的头,这其实会带来一些理解压力。
Gemini和GLM一样的毛病,ChatGPT-4o直接把第一句的following硬翻译成了追踪,Pass。
Claude对第一个句子的翻译,也是尬的一批,6层xxx的第5层中。没有人这么说话的。
除了上面两道对象是纯文本的测试题,日常看论文时,另一个特别让我看了心情复杂的一点就是,文本中被插入一堆数学符号。翻译器很容易被搞懵逼。
所以我也就把这一点作为第三大题,测试下这八个模型是怎么处理这些数字符号的。
文本还是用的《Attention Is All You Need》里的一段嵌入数学公式的内容。

总体来看,各家AI大模型对于内嵌数学公式的理解,其实都表现的还挺好的。
尽管 d² 的数学符号格式在排版上,有些模型处理的不够规整,但逻辑表达并没有什么混乱。
DeepSeek和子曰翻译2.0在处理技术性内容时,能够兼顾术语的准确性与说人话的表达方式,这一点明显胜过其他几个模型。
我在做这个测试的时候,还发现了一个很明显的点,就是最后一句话。
xxx,the approach we take in our model.
很明显地,这句话不应该与前一句区分开。
因为在中文语境中,它实际上是对前述内容的补充说明。但是除了子曰翻译2.0外的七家大模型,全都给隔离翻译了。
一个逗号,给7个大模型都忽悠过去了。。。

一套流程全部测下来,只说中英互译的话,你会很明显地感受到在说人话方面,有道这个子曰翻译2.0,是真的让我意外的觉的牛逼。
在没活别硬翻上,DeepSeek R1、子曰翻译2.0,ChatGPT-4o基本算是一个梯队的,专业术语知道保留,不瞎玩。
至少在我自己的测试中,最让我意外的一点,还是有道的子曰翻译2.0是效果最好的,这个点其实蛮让我意外。
但是同时也确实验证了一个“共识”。
在垂直场景里,这些积累了N多年数据的行业巨头,手上握着的资源和数据,确实不是一些通用大模型公司能匹敌的。
在我找出了我觉得目前最好的翻译大模型,准备就让它以后来帮我看论文读技术文章的时候,我发现。。。
沉浸式翻译没给子曰翻译2.0留API接口,接不进去。。。
而有道自己的产品虽然做的很不错,但是对于我这种每天在各种英文网站里来回蹦跶还要刷X和在arXiv上扒拉论文的人来说,体验路径确实有一点长。。。
这一下子给我整不会了。。。
不过如果是习惯用应用的,或者是手机主力党,那我还是无脑推荐你去有道他们自己的产品里面用。
比如他们的有道翻译和有道词典。
截图翻译、PDF翻译啥的都全乎,同传啥的也都有,这个里面的AI翻译就是子曰翻译2.0。
但是最可惜的就是没有我想要的浏览器翻译插件。
所以,在我犹豫了1分钟之后,为了方便,不用来回多开页面,省下时间安心做科普阅读。
我还是做了一个非常傻der的决定。
自己用AI手搓一个能接子曰翻译2.0API的论文专用的翻译器插件。。。
EMMMMMMM。
这个插件翻译效果是这样子的。

这个翻译插件的用户体验效果肯定没有那些商用插件好,但是吧,也是一个无奈之举。翻译质量,比体验重要。
老规矩,这个插件我也放在了公众号后台里,大家随意取用,直接公众号后台私信我"fy",系统就会自动发送你文件了。
插件的安装和API的接入,其实都特别简单。
先说API怎么获取。
直接进下面有道的AI开放平台申请API:
https://ai.youdao.com/modelTranslation.s
在最上面的导航栏里,选择产品服务,里面有个大模型翻译,点击即可。
选择立即使用。
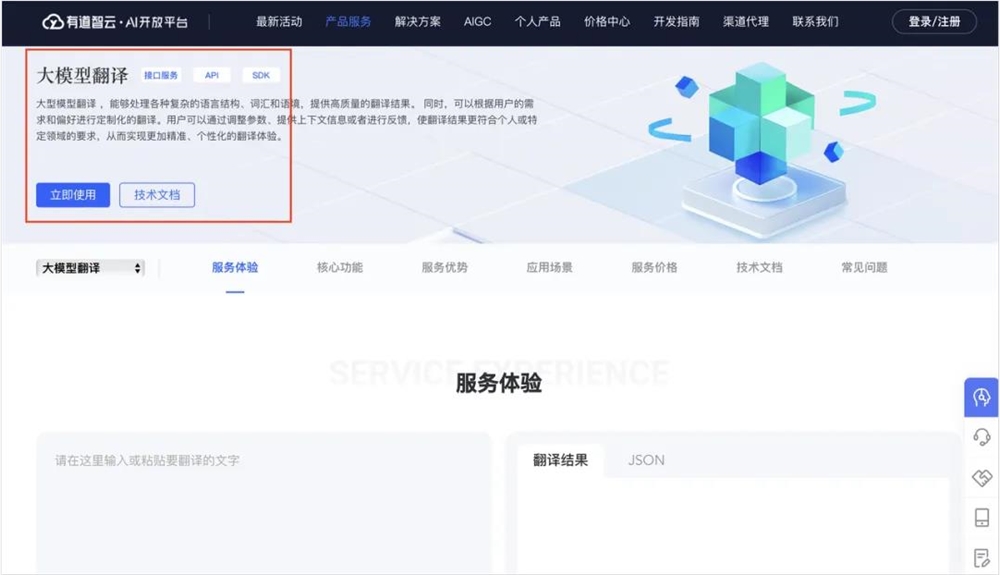
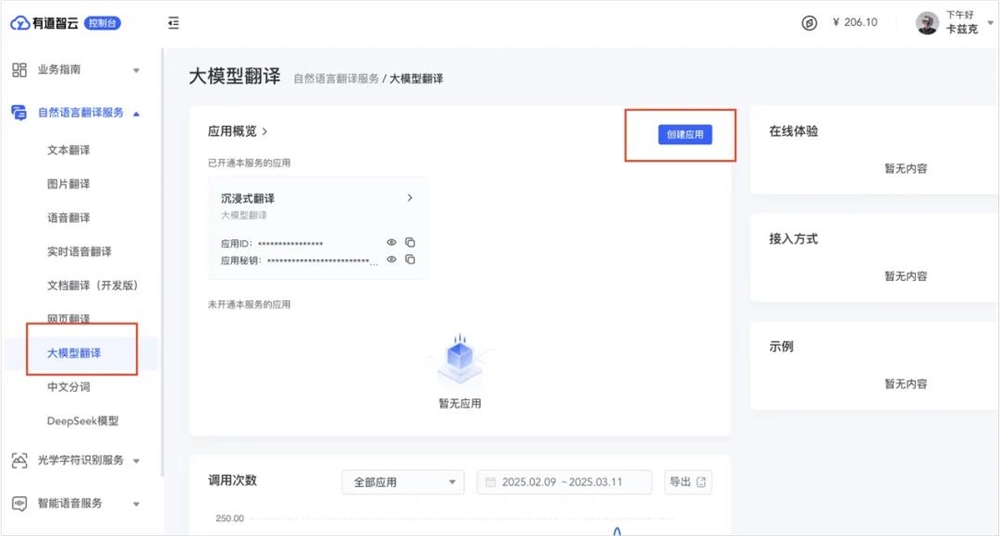
在左侧导航栏里选择自然语言翻译服务里的大模型翻译,点击创建应用。
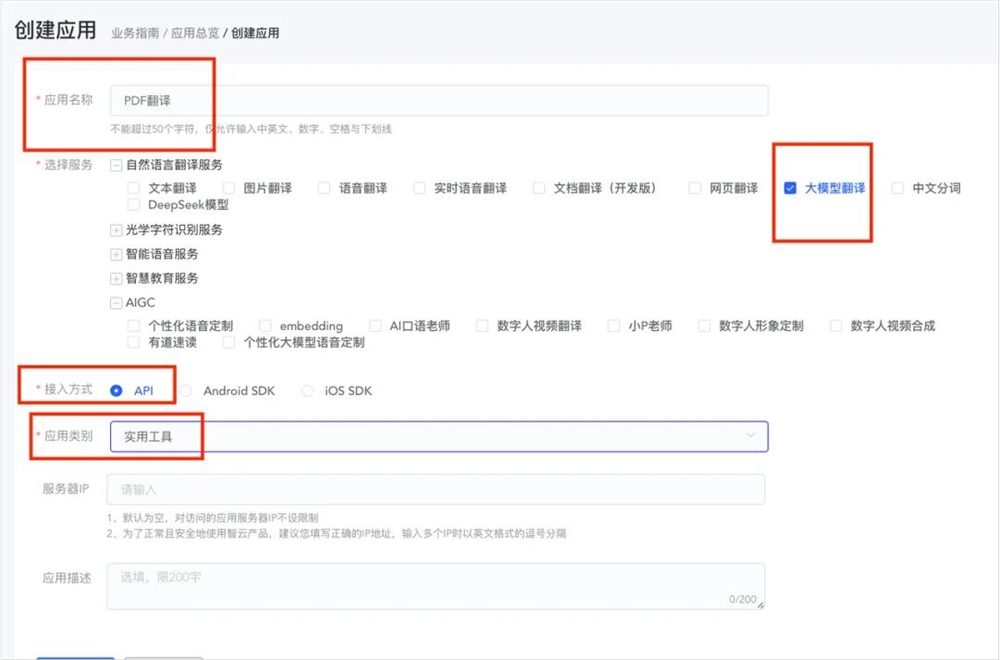
应用名称可以随便写,我写的是:PDF翻译,选择服务栏里要选:大模型翻译,接入方式选:API,应用类别直接选:实用工具。
选完这四项,直接点确认就行。
下面这俩其实就是你的应用ID和秘钥了。
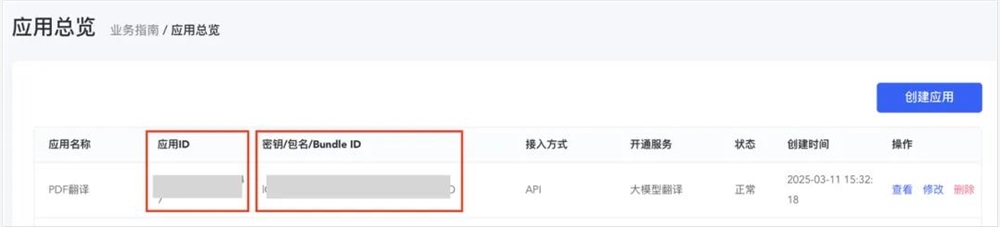
在有道API平台,一实名注册就会送50块钱的体验金。。。
基本够用一阵子了,大概能高质量地处理个三五千页PDF。
至于我手搓的论文翻译插件的安装也很简单。
按下面的指导图,一步一步来就行。
第一步就是解压缩我给你的翻译插件.zip。

然后打开谷歌浏览器,点右上方三个点按钮,进入管理扩展程序。
一键把文件拖进来,就能自动安装。
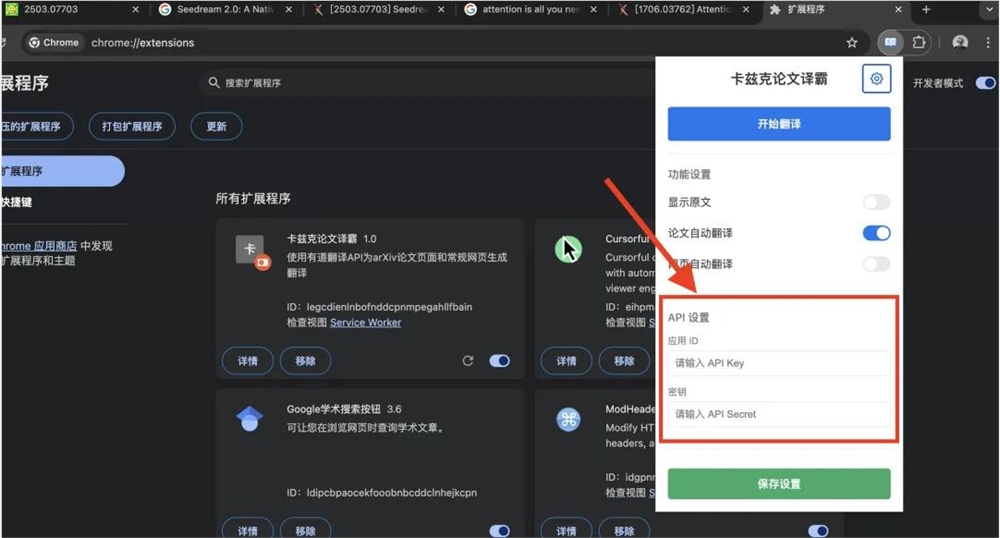
打开扩展程序按键,把【卡兹克论文译霸】置顶。
点击这个设置按钮。
输入你在有道API云平台,注册得到的API key和API Secret,点保存设置就能用了。
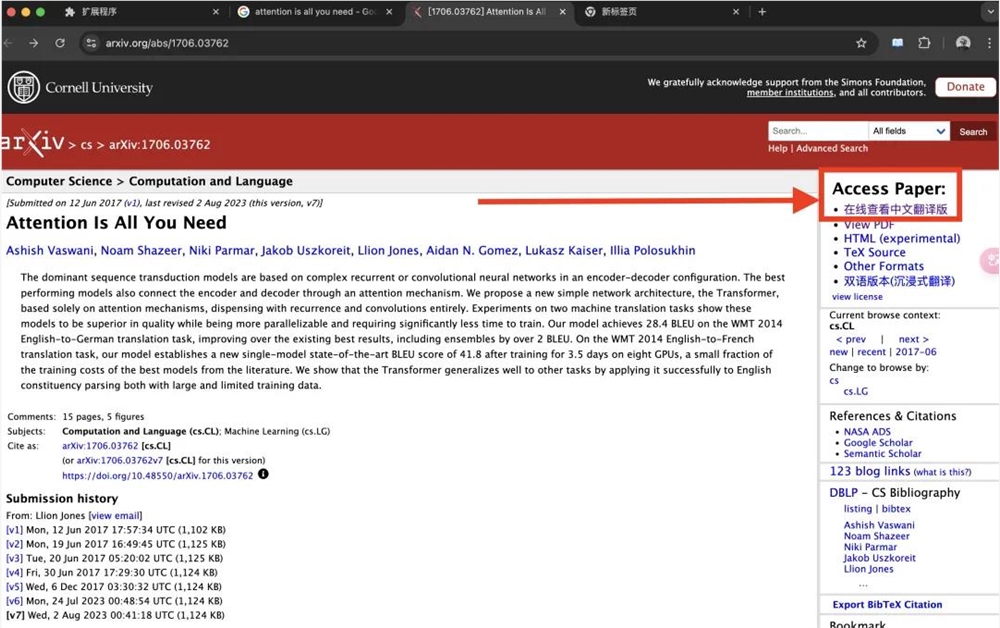
安装好插件,你刷新一下arXiv,你就会发现右边就有个【在线查看中文翻译版】的按钮。
点进去后,即可开始纯享版论文翻译。你可以点击隐藏原文,直接就是个子曰翻译出来的中文版。也可以,一键改变布局,原文译文排版,就像下面这样。
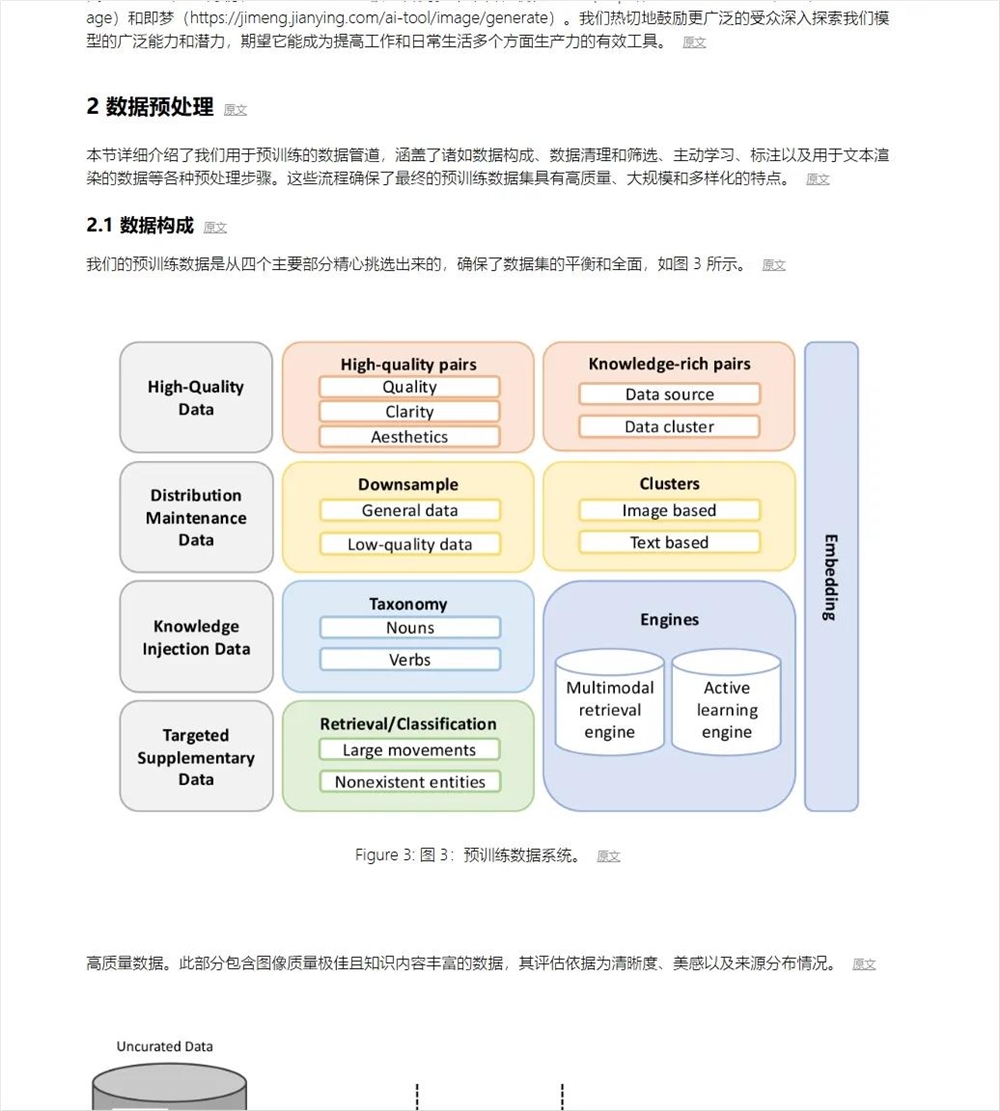
也支持,图文混排。
一些网页也行。

整个流程,真的几分钟就能搞定。
接下来就能在中英互译的论文世界里遨游了。
说实话,我这个手搓的小插件,很蹩脚,如果有道或者沉浸式翻译能看到我这篇文章,我希望:
要么有道出个插件,要么沉浸式翻译支持一下有道的API吧。。。
真的,我觉得浏览器翻译这个场景,还是蛮刚需的。
当然,如果你觉得这个插件太矬了(确实也挺挫),那也可以把PDF下载下来,扔到有道翻译里面直接翻译。
或者直接用他们的截图翻译吧。
不过,如果你跟现在的我一样,就喜欢浏览器上苦读英文文献,也追求翻译质量,那我觉得,真的可以考虑凑合用一下我这个小破插件。
祝我们都能在AI和翻译的世界里越走越远,再也不用为语言门槛而挠头懊恼。
愿你我的AI路上,都能走的更远。
共勉。
(举报)